Databend on AWS/EKS
Over the Christmas silent period, I got my hands on Databend, a data warehousing solution intended to provide an easily scalable, cloud-first, SQL-based data engine. The keywords bingo speaks for itself: it’s written in Rust, friendly with containers/Kubernetes (k8s), elastically scalable, and uses Raft as a consensus algorithm instead of Paxos. In short, it fits all the last five years’ fashion trends in data warehousing. What specifically appealed to me was the ability to use cloud object storage as a storage backend and the isolation between compute and storage. Benchmarks comparing its performance with alternative open-source solutions ClickBench and with cloud alternatives show some interesting results.
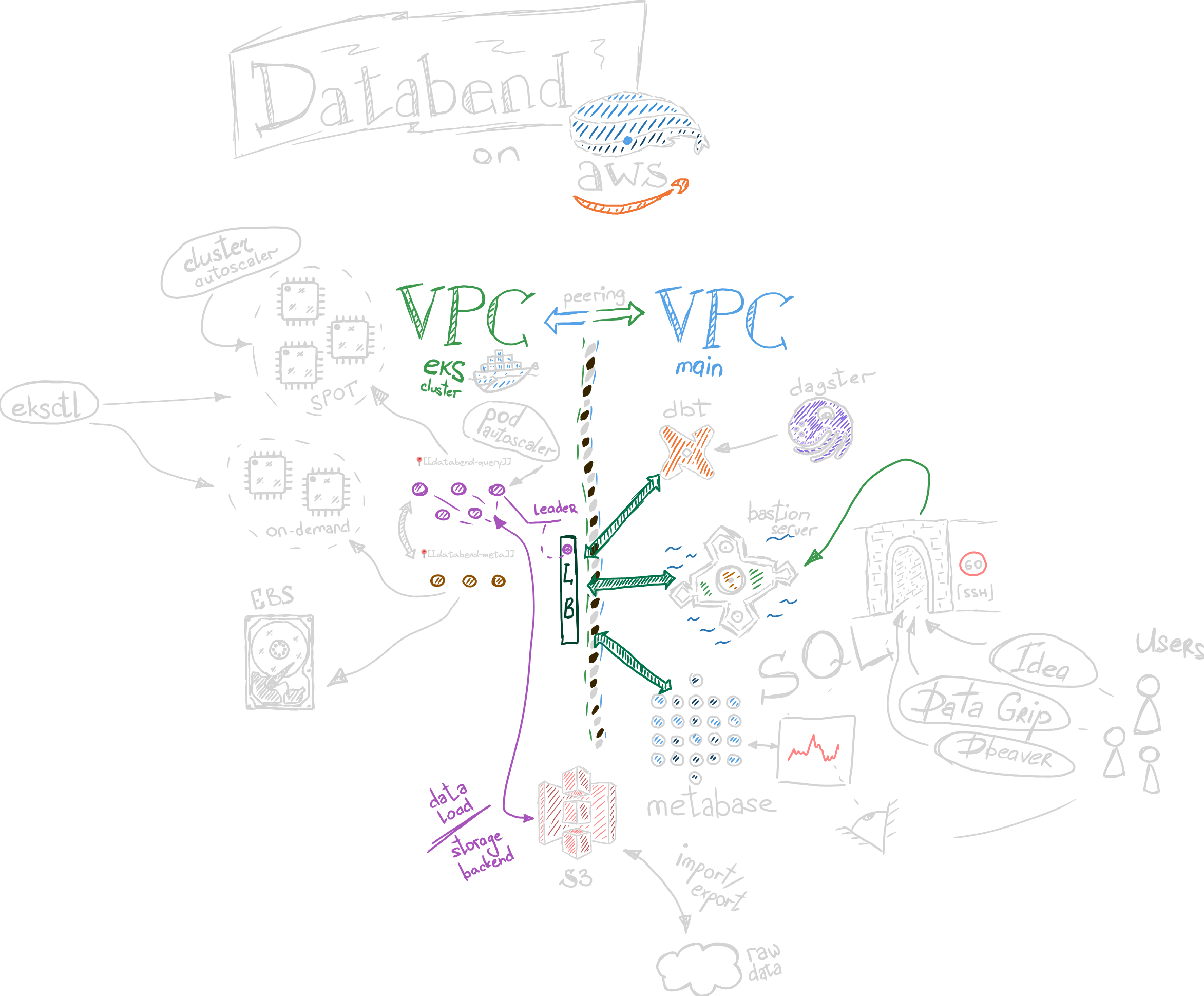
I briefly went through the documentation to figure out how to try things out - and, of course, there was a tutorial on how to set it up locally with MinIO or locally with Docker. I didn’t even try this because what I would get locally in that case would only be a loosely implemented SQL dialect, whereas I needed the power of distributed computation at my fingertips. So, I went with the K8S setup, even though, having only a handful of microservices in the current organization, we don’t use it in production. It took me no time to discover a great way to provision and control a k8s cluster on AWS without the need for Terraform - eksctl. After some dancing with the documentation and setting up the recommended helm charts and applications (beware, “recommended” in this guide is almost always mandatory - and even if not, you surely want to monitor your cluster after setting it up).
I decided to use a few smaller on-demand nodes for databend-meta nodes and a node group with spot instances having more beef in terms of networking/memory/CPU (in that order), with the ability to interchange things in the future. After some tuning, I was able to find a setup that was giving enough performance without breaking the bank and managed to reproduce some production queries we use with AWS Redshift.
Getting this result on the client was already quite pleasant, where I thought it’s about to start working as intended:
34 rows read in 73.337 sec. Processed 753.26 million rows, 100.63 GiB (10.27 million rows/s, 1.37 GiB/s)
Though it might seem not much for modern bandwidth, for a medium-complexity analytics query, that demonstrated some potential to me.
A nice thing for integration - a native JDBC driver was available, together with the ability to connect through a MySQL interface, which easily allowed integrating and trying out a few existing data tools.
Overall, I am pretty happy with the setup. Key benefits that I noted for myself:
- Performance: It is so far super-good-enough for our main use-cases.
- Isolation: The engine is mainly performing/optimizing analytical queries; the data is stored elsewhere.
- Integrity: The tool provides very good interfacing with the outside world without jeopardizing the consistency of the tool.
Key things I’ll keep in mind before going full speed with the solution:
- Maturity/Stability: The tool is quite young, and some of the behaviors I observed proved it:
- User-space queries causing cluster shutdown.
- Sometimes misleading error messages, especially depending on the connector/driver used.
- The UDF library is not as extended as for more well-established tools on the market.
All in all, this leads me to think I will keep the tool on the radar and explore possibilities of using it for non-critical use cases, where performance prevails over stability and accuracy. I also started using it more for ad-hoc data analysis (loading a file from S3, performing an analysis, and loading it back). For those tiny purposes, the tool is great, and I think this is the best way to gain more traction. Wishing the team great success with the development.