Simple data-driven applications in Clojure
Sometimes the information from the data lake/warehouse/pond/whatever simply needs to be exposed via the REST-api. Just getting the tooling right sometimes may be troublesome. Here’s an example on how things can work out in clojure.
Let’s say we have an SQL-based engine like Presto (or Presto) as the main interface to the datalake. Let’s check how we can leverage the power of Clojure to build a simple application for fetching the data from Presto.
- Getting started with a small template (ring application with presto driver managed by mount).
lein new ferry62 changes +presto
- Checking the project structure.
.
├── dev
│ └── user.clj # REPL (helpers to get best UX from REPL-driven development)
├── Dockerfile
├── project.clj
├── README.md
├── resources
│ └── queries
│ └── example.sql # SQL templates
├── src
│ └── changes
│ ├── api.clj # API routing ("/path" -> handler mappings)
│ ├── core.clj
│ ├── handlers.clj
│ └── presto.clj
You won’t see to much of Clojure code here. It is mainly defined by it’s interfaces:
- Data source (presto engine)
- API
Easy!
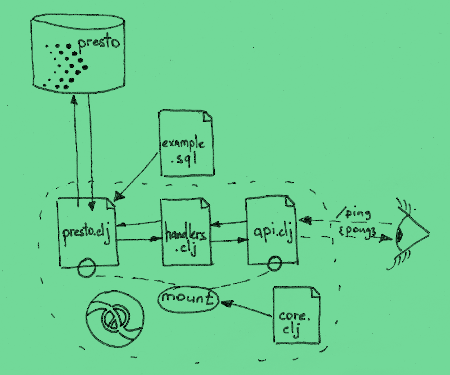
Even if you never worked with Clojure, it’s quite easy to get started. Once you fight your way through the syntax, you may realise that there are not so many things happening in the application apart from what you actually wanted to do - link your data source to the API.
Let’s get our hands dirty!
First you’d need to install leiningen - the tool for building Clojure projects and managing project dependencies.
You can do it with brew in Mac, or by simply following the instructions on the website to install it as a script.
lein run
curl http://localhost:4040/ping
And if you’re into REPL:
lein repl
You can docker-compose yourself an hdfs+hive+presto setup locally:
git clone https://github.com/big-data-europe/docker-hive
cd docker-hive
docker-compose up -d
# ... wait until presto server starts
… and start exploring the storage and run the operations against it
(start)
(presto-query "SELECT 1")
; -> {:col0 1}
Let’s get a bit behind the scenes of what actually happened here.
(start) is a function call that tells mount to start the applicatoin.
Mount is very compact component management library pursuing the goal of having minimal feasible way of
managing statefull components of your application. I personally really like this approach for both REPL-driven
development process and also for managing artifacts.
In our scenario there are only two components: the API and the database connection.
presto-query is a helper function that’s intended to simplify the process of working with the data from REPL.
At this point we simply started our application and made sure that our Presto connector works.
What if we’d actually want to enrich our application with new functionality?
Here hugsql comes into play and allows you to structure the interactions with your database in a form of template queries.
-- resources/queries/example.sql
-- :name sample-fields-query :? :1
-- :doc sample fields echo query
SELECT
:name AS name
,:age AS age
,:date AS datem
Here is the way those functions can be rendered:
(hugsql/def-sqlvec-fns "queries/example.sql")
Here’s the example of using the rendered template functions:
(let [db-vec (presto/sample-fields-query-sqlvec
{:name "Banana" :age 25 :date "2018-11-11"})
db-result (presto/query-cached db-vec)]
API routing is simply defined as a case statement in api.clj:
(case (:uri request)
"/sample" (handlers/sample-fields request)
"/ping" (handlers/pong request)
{:status 400 :body (str "bad request: " (:uri request))})
The API handler functions do nothing but convert one data structure into another.
I think this is the main selling point of Ring-based applications, if you want, you can manage completely immutable codebase for your API handlers.
(defn pong
[request]
{:status 200
:body {:result :pong}
:headers {"Content-Type" "application/json"}})
Those are the main points where the application may be extended.
- api.clj - for adding new routes
- handlers.clj - for the data transformation/mapping of the API requests to the database queries
- *.sql resources file - for managing the database queries
In a follow-up posts I’ll explain how to use different REST (or GraphQL) backends and handle other storage solutions.